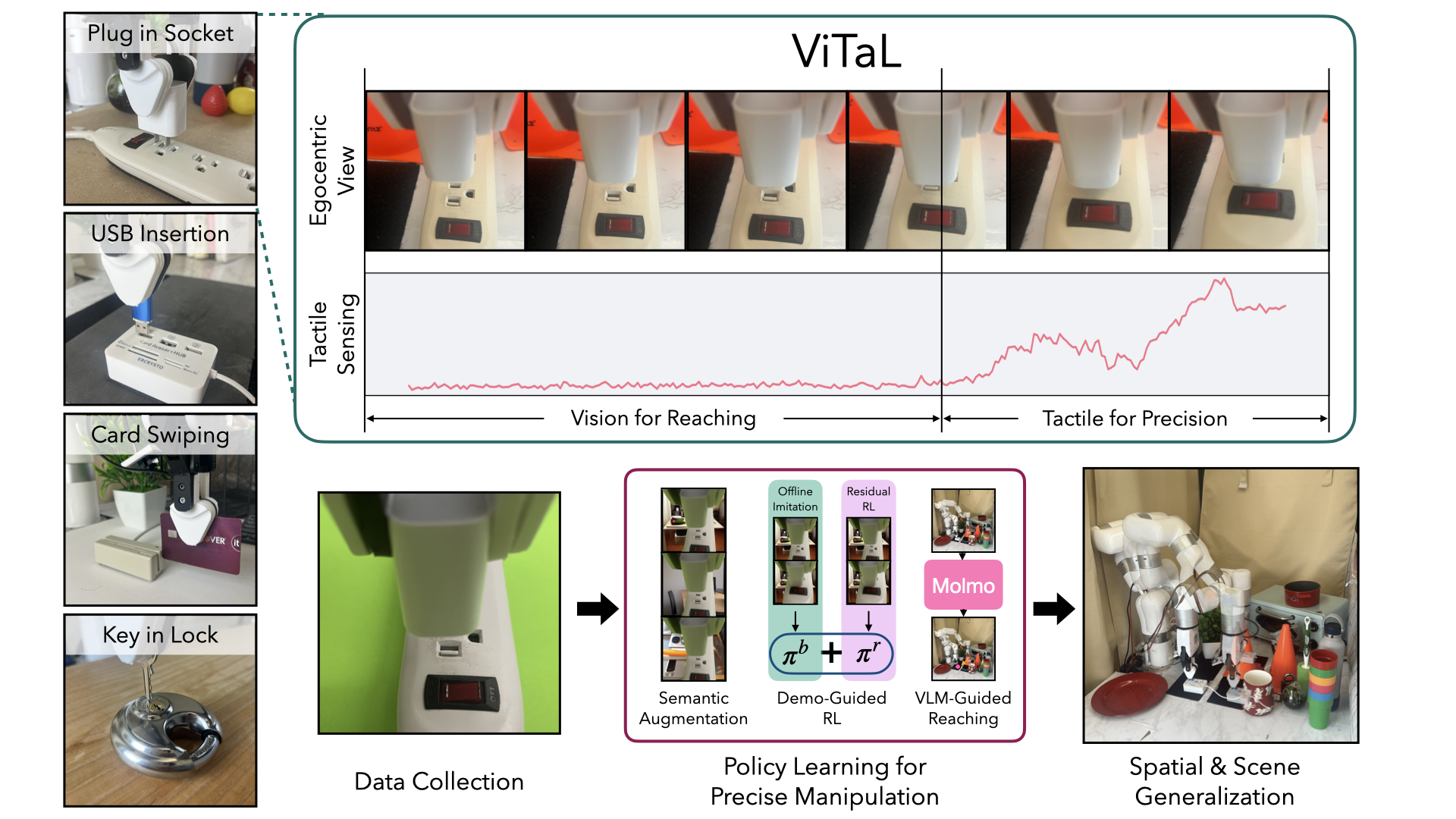
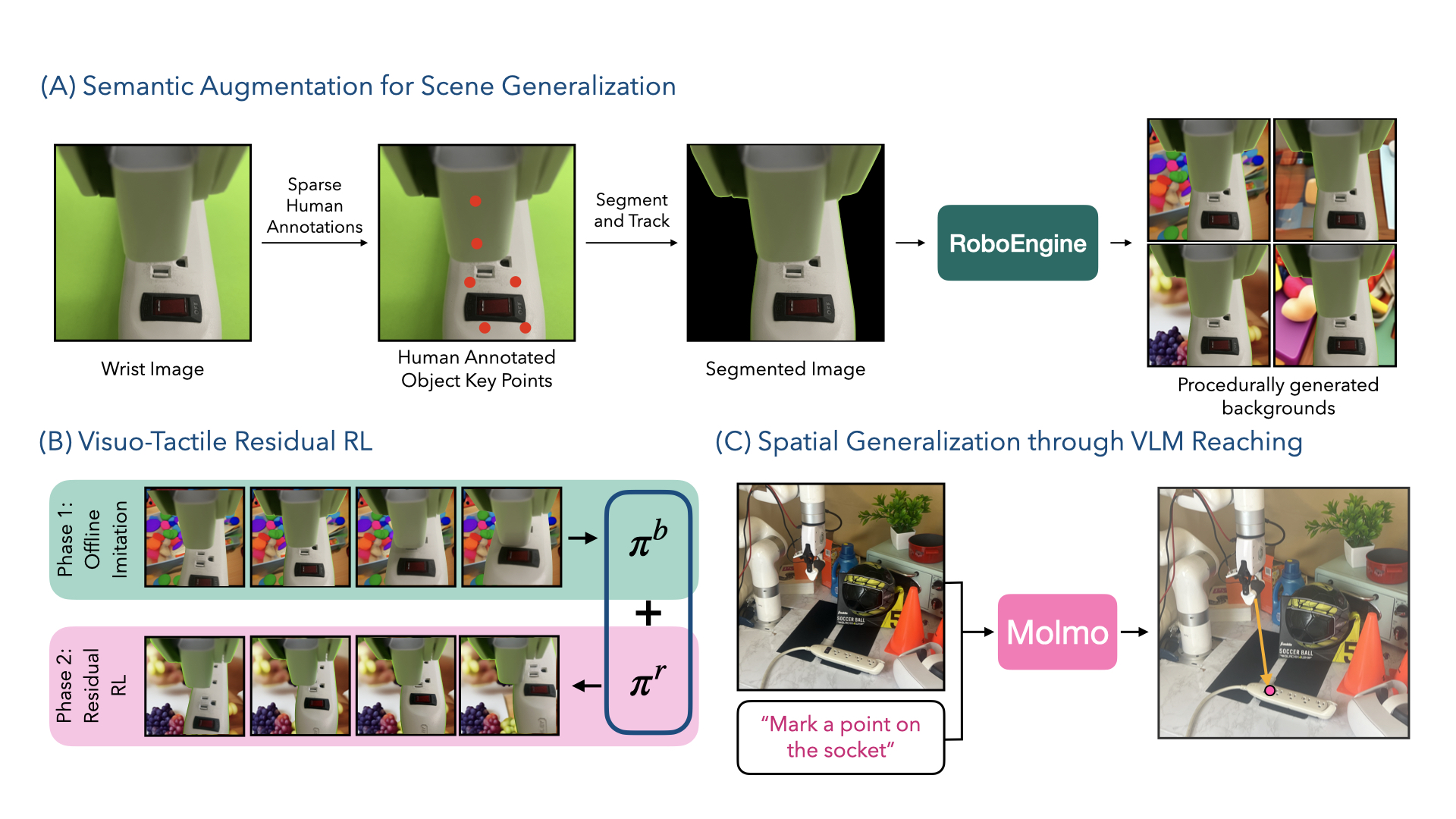
Data-driven approaches struggle with precise manipulation: imitation learning requires many hard-to-obtain demonstrations, while reinforcement learning yields brittle, non-generalizable policies. We introduce VisuoTactile Local (VITAL) policy learning, a framework that solves fine-grained manipulation tasks by decomposing them into two phases: a reaching phase, where a vision-language model (VLM) enables scene-level reasoning to localize the object of interest, and a local interaction phase, where a reusable, scene-agnostic VITAL policy performs contact-rich manipulation using egocentric vision and tactile sensing. This approach is motivated by the observation that while scene context varies, the low level interaction remains consistent across task instances. By training local policies once in a canonical setting, they can generalize via a localize-then-execute strategy. VITAL achieves ~90% success on contact-rich tasks in unseen environments and is robust to distractors. VITAL's effectiveness stems from three key insights: (1) foundation models for segmentation enable training robust visual encoders via behavior cloning; (2) these encoders improve the generalizability of policies learned using residual RL; and (3) tactile sensing significantly boosts performance in contact-rich tasks. Ablation studies validate each of these insights, and we demonstrate that VITAL integrates well with high-level VLMs enabling robust, reusable low-level skills.
The following videos are learnt ViTaL policy rollouts being executed on the robot at 1x speed.
The following videos are rollouts being executed on the robot combing reaching and precise manipulation with spatial and environmental variations.
The following videos show rollouts with the fisheye view (bottom-left) and tactile readings (top-right) displayed simultaneously.
The following videos are rollouts of robot doing precise manipulations with human perturbations.
The following videos are rollouts of robot doing precise manipulations with policy training with different robot and environment setting.
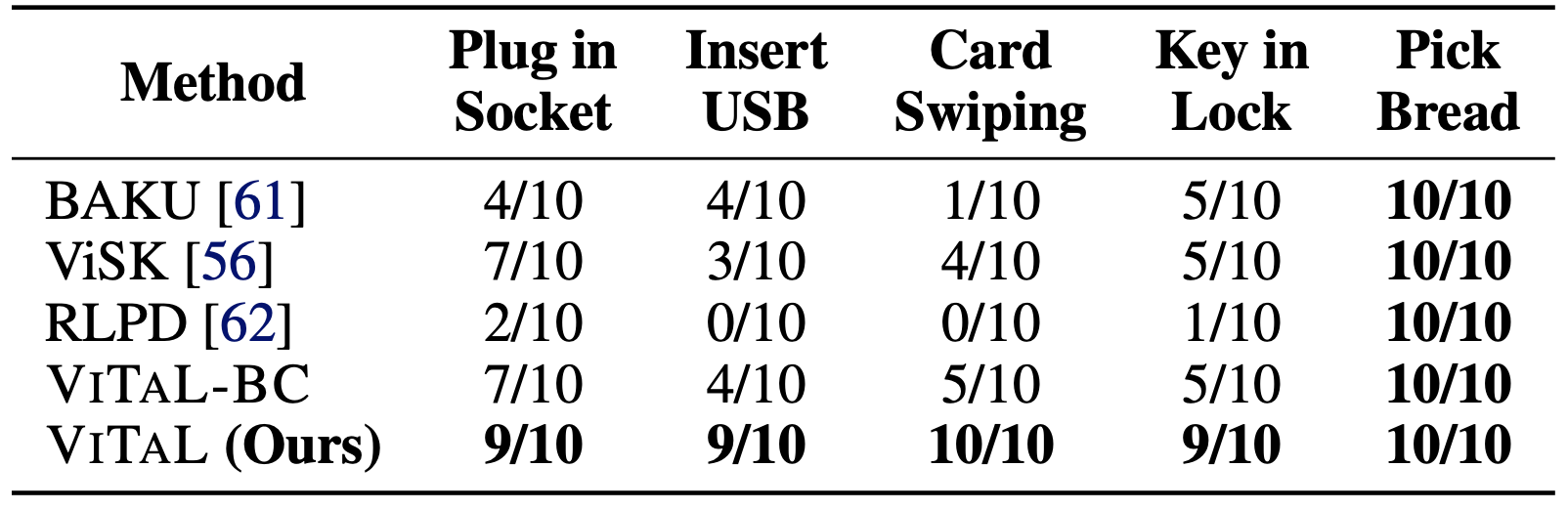
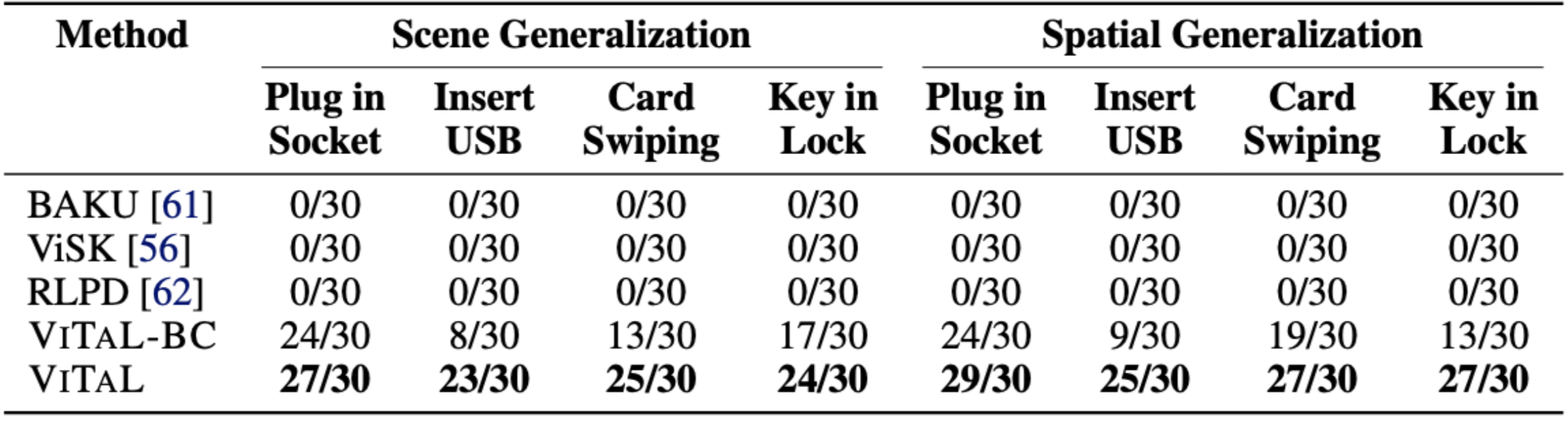
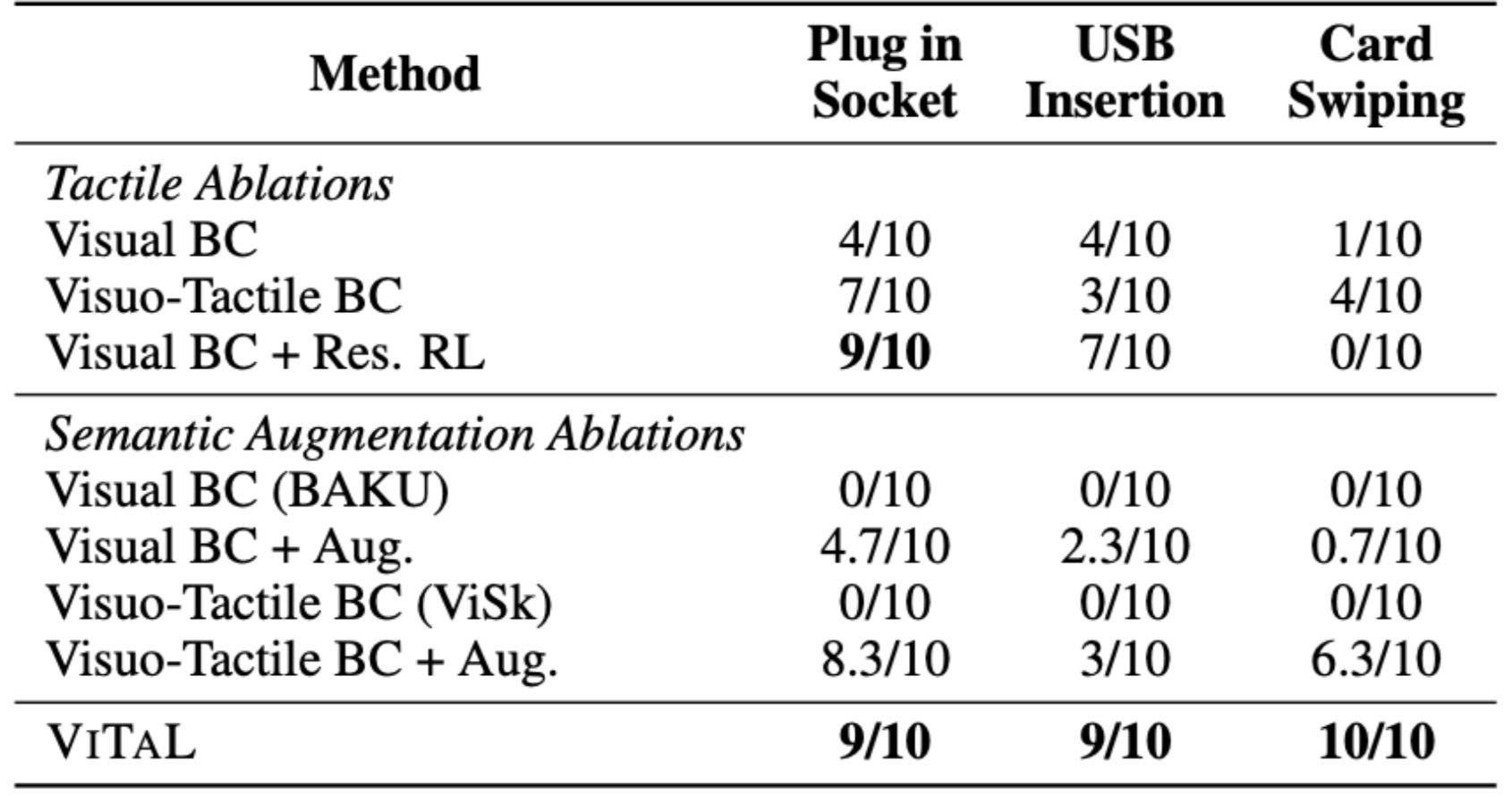
We run 10 evaluations each across 3 seeds, on held out unseen target object positions for each task.